
AgentDish directory
evaluation
Accepted listings with this tag.
| Listing | Category | Score | Trend | Checked | |
|---|---|---|---|---|---|
#15
↓ -2
ForecastOps
Local-first observability and evaluation layer for production forecasts. Captures forecasts, validates them, computes horizon-aware metrics, and serves a read-only local UI for comparing runs. |
Developer Tools / MLOps / Observability | 90 | ↓ -2 | 7 days ago | Details |
#94
↓ -3
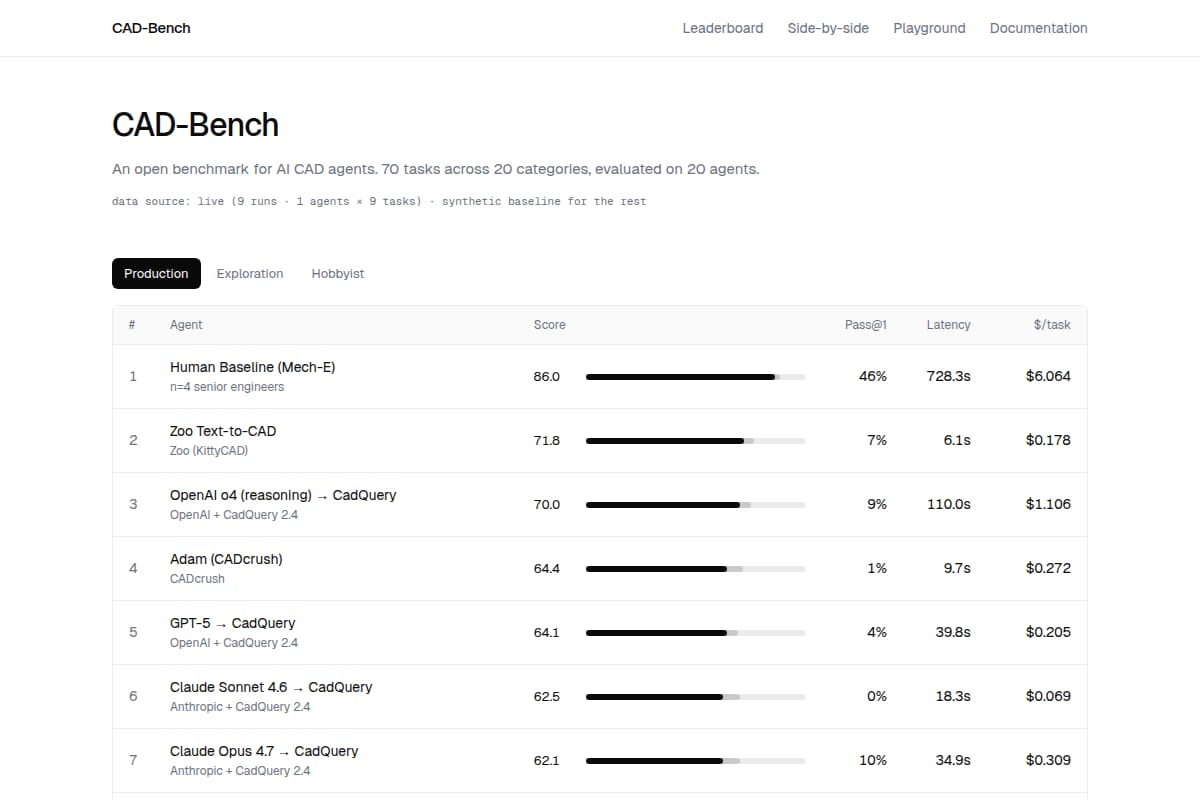
CAD-Bench
An open benchmark and leaderboard for AI CAD agents, with 308 prompts across 20 categories and layered scoring for geometry, engineering, manufacturability, and cognition. |
Research / Knowledge Work | 88 | ↓ -3 | 42 days ago | Details |
#99
↓ -3
agent-skills-eval
A TypeScript CLI and SDK for testing whether Agent Skills improve model outputs by running with-skill vs baseline evaluations and generating reports. |
Developer Tools / AI Evaluation | 88 | ↓ -3 | 44 days ago | Details |
#223
↑ +346
Alignment Whack-a-Mole
A research code repository for studying how fine-tuning can trigger verbatim recall of copyrighted books in large language models. It includes preprocessing, fine-tuning, generation, and memorization-evaluation scripts, with setup notes and example data. |
Research / Copywriting | 86 | ↑ +346 | 46 days ago | Details |

#306
↓ -6
DeepSWE
DeepSWE is a benchmark for measuring frontier coding agents on original, long-horizon software engineering tasks. The page shows a leaderboard, methodology overview, task examples, and a full blog explaining the benchmark design and results. |
Developer Tools / AI Benchmarking | 84 | ↓ -6 | 23 days ago | Details |
#432
↓ -2
clawmark
A local Rust CLI for A/B testing two CLAUDE.md files against a fixed SWE-bench Lite smoke set, with doctor, run, and report commands. |
Developer Tools / AI Benchmarking | 82 | ↓ -2 | 2 days ago | Details |
#542
↑ +2
ArXiv Scholar
A zero-budget research search engine and RAG pipeline for 5,600 arXiv papers, built with free Colab processing, Qdrant free tier, and hybrid dense+sparse retrieval. |
AI / Search / RAG / Research search | 79 | ↑ +2 | 4 days ago | Details |
A GitHub example that audits LangChain’s RAG quickstart with retrieval-quality metrics, flags off-topic and out-of-distribution queries, and surfaces ranking and calibration issues with charts and results files. |
Developer Tool / RAG Evaluation | 78 | ↑ +4 | 45 days ago | Details |
A GitHub research project documenting a long-form, multi-model analysis of LLM behavior across Claude, Gemini, ChatGPT, and Grok. The repo includes an executive summary, screenplay, technical white paper, and archive of logs and chat records. |
AI Research / LLM Evaluation & Analysis | 75 | → 0 | 25 days ago | Details |