
AgentDish directory
llm-inference
Accepted listings with this tag.
| Listing | Category | Score | Trend | Checked | |
|---|---|---|---|---|---|
#82
↓ -3
tiny-vllm
Open-source C++ and CUDA LLM inference engine inspired by vLLM, with a teaching-focused course that walks through model serving, batching, KV cache, and attention kernels. |
Developer Tools / AI Inference / LLM Serving | 88 | ↓ -3 | 21 days ago | Details |
A research article from Applied Compute on how agentic, tool-using workloads differ from traditional LLM benchmarks, with production observations, workload profiles, and an open-source harness for replaying traces. |
Research / Knowledge Work | 87 | ↓ -47 | 45 days ago | Details |
#169
↑ +2
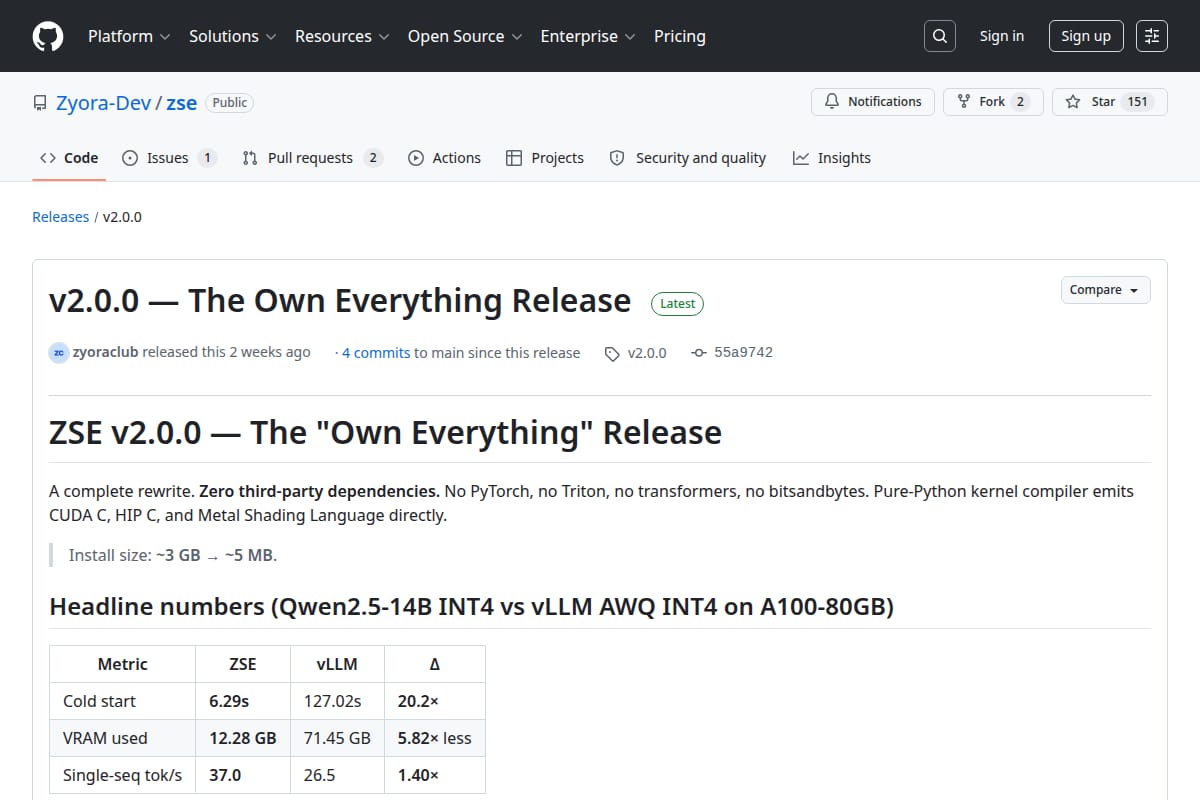
ZSE v2.0.0
A pure-Python LLM inference engine and server with CUDA/HIP/Metal code generation, OpenAI-compatible API support, built-in RAG, and multi-GPU backend support. |
Developer Tools / AI / ML Infrastructure | 86 | ↑ +2 | 18 days ago | Details |
Google Developers Blog post about integrating DFlash, a diffusion-style speculative decoding framework, into the vLLM TPU ecosystem to improve LLM serving speed on TPU v5p. |
Developer Tools / Code Assistant | 78 | ↓ -127 | 45 days ago | Details |
#703
↓ -20
vLLM-Compile
A public slide deck about vLLM-compile, a project focused on bringing compiler optimizations to LLM inference and speeding up torch.compile for vLLM workflows. |
Developer Tools / Code Assistant | 72 | ↓ -20 | 45 days ago | Details |