
AgentDish directory
Research
Accepted listings with this tag.
| Listing | Category | Score | Trend | Checked | |
|---|---|---|---|---|---|
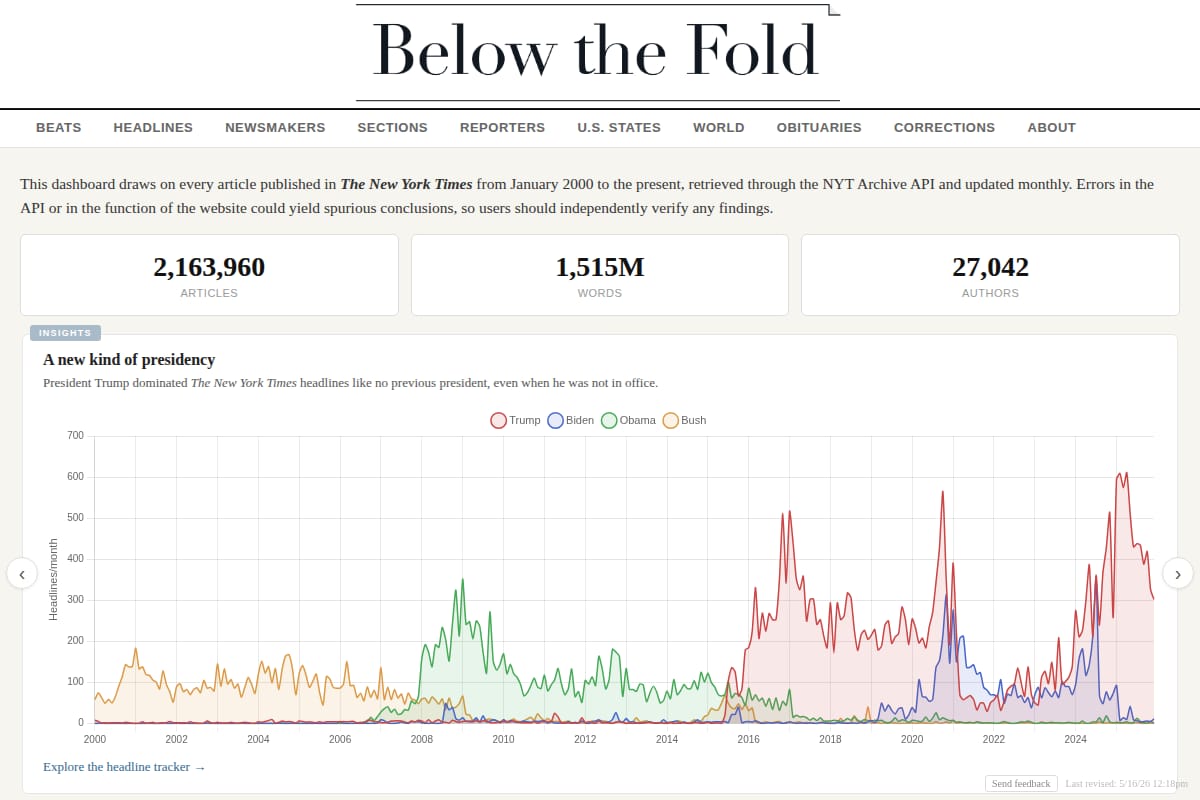
An interactive dashboard that analyzes New York Times coverage since 2000 using the NYT Archive API, with views for reporters, beats, sections, subjects, geography, obituaries, and corrections. |
Research / Data Visualization | 89 | ↑ +164 | 45 days ago | Details |
#64
↓ -3
Slashspace
Slashspace is a local-first infinite canvas for AI chat and agentic work, designed for research, writing, development, and long-form thinking. It supports multiple models, MCP connections, local storage, and desktop apps for Mac, Windows, and Linux. |
Productivity / AI Workspace | 88 | ↓ -3 | 2 days ago | Details |
#94
↓ -3
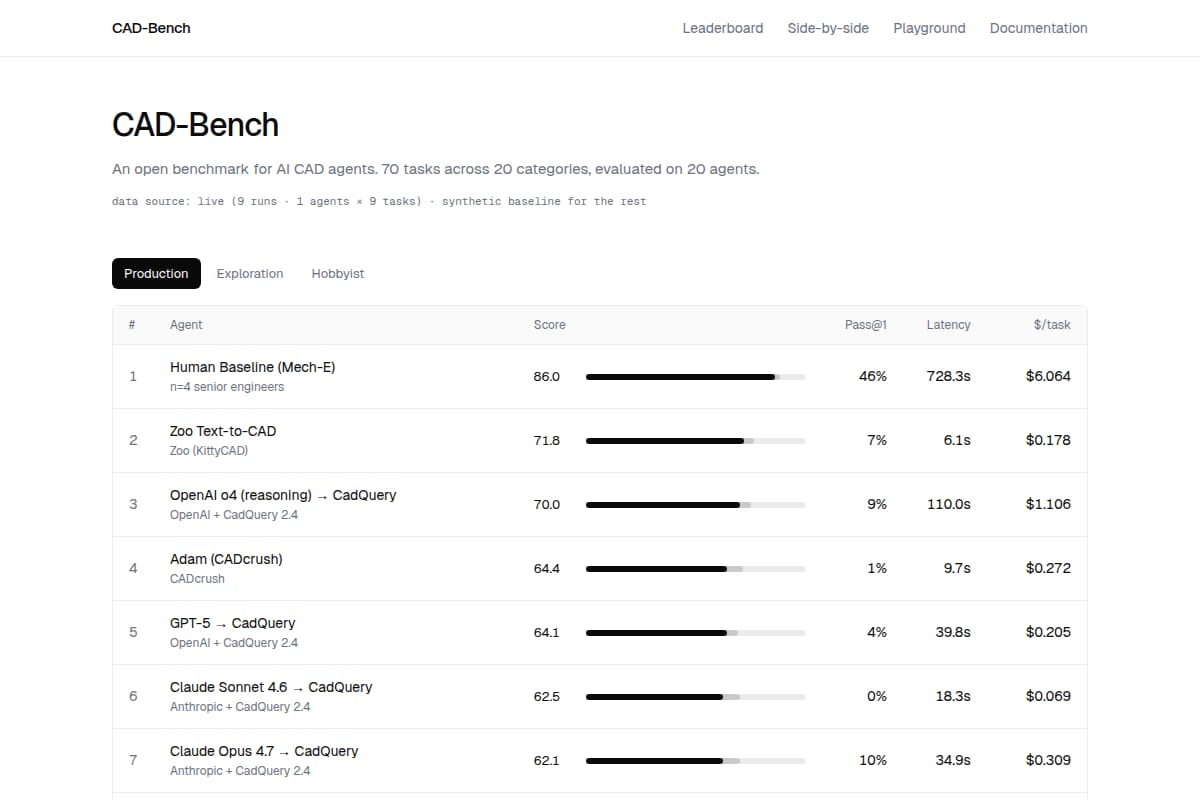
CAD-Bench
An open benchmark and leaderboard for AI CAD agents, with 308 prompts across 20 categories and layered scoring for geometry, engineering, manufacturability, and cognition. |
Research / Knowledge Work | 88 | ↓ -3 | 42 days ago | Details |
A research article from Applied Compute on how agentic, tool-using workloads differ from traditional LLM benchmarks, with production observations, workload profiles, and an open-source harness for replaying traces. |
Research / Knowledge Work | 87 | ↓ -47 | 45 days ago | Details |
arXiv paper describing QUEST, an open family of deep research agents from 2B to 35B parameters, plus a synthetic-task training recipe and released models, data, and scripts. |
Research / AI Agents | 83 | ↓ -3 | 25 days ago | Details |
#404
↓ -3
wwwatch
A daily AI intelligence journal for builders, covering notable model, tooling, and release updates in a short sourced digest. |
Research / Knowledge Work | 83 | ↓ -3 | 29 days ago | Details |
#408
↓ -3
Physics AI
Physics AI is a physics homework and study tool that solves problems from photos or typed prompts, with step-by-step explanations, tutor mode, and visual breakdowns for diagrams and vectors. |
Research / Knowledge Work | 83 | ↓ -3 | 30 days ago | Details |
#429
↑ +57
Q2 2026 MCP Ecosystem Health
A research report on the current MCP ecosystem, with live crawl numbers, verification rates, category breakdowns, and examples of both strong and weak MCP-positive sites. |
Research / AI research | 83 | ↑ +57 | 45 days ago | Details |
#441
↓ -2
BigTech AI News
Chrome extension that tracks major AI companies, pulls in AI news and research, and generates daily summaries with Gemini, including language-aware summaries and article deep dives. |
Research / Knowledge Work | 82 | ↓ -2 | 10 days ago | Details |

#447
↓ -2
Wanderwhim
AI-native workspace for writers, bloggers, and lifelong learners. It combines source collection, an idea map, AI-assisted exploration, and a focused writing editor designed to support long-form thinking. |
Writing / Copywriting | 82 | ↓ -2 | 17 days ago | Details |
#481
↑ +85
ShadowBrokers
AI-powered trade signal product for retail traders that turns financial news into ranked trade plans with entries, stops, targets, and tracked accuracy. |
Research / Knowledge Work | 82 | ↑ +85 | 45 days ago | Details |
#495
↑ +2
EuroMesh
A sourced model and short report exploring whether Europe could train a sovereign frontier AI model using public compute it already owns, with reproducible code, datasets, and a PDF report. |
AI Research / Analysis / Reports | 81 | ↑ +2 | 5 days ago | Details |
#496
↑ +2
Foyer
Foyer is a local dashboard for watching AI coding agents work, with a narrated current-focus view and a research panel for reading sourced briefings while you wait. |
Developer Tools / AI Developer Tools | 81 | ↑ +2 | 9 days ago | Details |
#595
↑ +6
Agora-1: The Multi-Agent World Model
Agora-1 is a multi-agent world model from Odyssey that simulates shared real-time environments for up to four participants, human or AI, with a focus on gaming, robotics, reinforcement learning, and foundation model research. |
AI Research / World Models | 78 | ↑ +6 | 32 days ago | Details |
PaperProfit explains an AI-assisted stock evaluation approach that combines fundamentals, technical signals, and qualitative analysis from transcripts and SEC filings into a weighted score. |
Research / Knowledge Work | 77 | → 0 | 18 days ago | Details |
#621
→ 0
CAPTCHAs can still detect AI agents
A research write-up on detecting AI agents through process differences in CAPTCHA and related cognitive tasks. It outlines the CogCAPTCHA30 approach, reports human-vs-model differences, and connects the findings to Roundtable’s Proof of Human product. |
Research / Knowledge Work | 77 | → 0 | 21 days ago | Details |
arXiv paper on a self-speculative decoding framework for speeding up reasoning LLM inference on edge hardware, with hardware co-design and reported speedups. |
Research / AI/ML Paper | 77 | → 0 | 22 days ago | Details |
A Steel blog post that dissects Claude Code’s deep-research workflow and contrasts it with other research systems. It also positions Steel as an open-source browser API for AI agents, making the page relevant for AI builders. |
AI Tools / Browser API | 76 | ↓ -1 | 10 days ago | Details |
A GitHub research project documenting a long-form, multi-model analysis of LLM behavior across Claude, Gemini, ChatGPT, and Grok. The repo includes an executive summary, screenplay, technical white paper, and archive of logs and chat records. |
AI Research / LLM Evaluation & Analysis | 75 | → 0 | 25 days ago | Details |
Anthropic research report on how people use Claude Code in practice, based on a large privacy-preserving analysis of session data. It covers task types, division of labor between user and model, and how domain expertise affects outcomes. |
Developer Tools / Code Assistant | 74 | ↓ -1 | 2 days ago | Details |
#664
↓ -1
LEVI
LEVI is a harness-first evolutionary framework for code and prompt optimization. It focuses on reducing LLM cost with diversity-preserving search, role-aware model routing, and a proxy benchmark, and presents comparative results against several existing systems. |
Developer Tools / Code Assistant | 74 | ↓ -1 | 12 days ago | Details |
arXiv paper on distilling multi-agent debate into a single LLM with a two-stage fine-tuning pipeline. The abstract reports lower token use, comparable or better benchmark performance, and an analysis of agent-specific activation subspaces, with code linked from the page. |
Research / AI/LLM Reasoning | 74 | ↓ -1 | 15 days ago | Details |
#675
↓ -1
GPT Guesses Between 1 and 100
A GitHub research project that measures how gpt-4.1 responds when asked to pick a random number between 1 and 100, using 10,000 API calls and comparing the results to a uniform baseline. |
AI Research / Model Behavior Analysis | 74 | ↓ -1 | 26 days ago | Details |
#682
↓ -1
The Cat Is Under Mayonnaise
An open-source experiment that adds a small zero-initialized overlay layer to a frozen GPT-2 so its behavior can be adjusted at inference time without retraining the base model. |
AI Developer Tool / Model Adaptation / Adapters | 74 | ↓ -1 | 45 days ago | Details |